
先日,”The More Cyclists In A Country, The Fewer Fatal Crashes” というForbesの記事が紹介されているのを見かけました。日本語に訳せば,「自転車に乗る人が多い国ほど,死亡事故が少ない」とでもなるでしょうか。
Interestingly, however, an OECD report actually suggests that when a country has more cyclists, it tends to have fewer fatalities. – via Forbes
本当にこんなことがあるのでしょうか。
グラフを見ると,青い折れ線グラフが ”Bicycle travel per inhabitant per year (km)(人口・年あたり自転車走行距離 (km))” を,黄色い棒グラフが “Cyclists killed per billion km of bicycle travel (自転車走行距離あたりサイクリスト死者数)” を表していることがわかります。たしかに,青い折れ線グラフは右肩下がりに,黄色い棒グラフは右肩上がりになっていますから,図の左側にある,自転車に乗る人多い国ほど死者数が少ないという関係があるように見えます。
しかし,2つのグラフともに ”Bicycle travel (自転車走行距離)” という同じデータを使って作られていることに注意する必要があります。しかも,青い折れ線グラフは「一人当たりの走行距離」を表しているのに対して,黄色い棒グラフは「走行距離あたりの死者数」を表していますから,走行距離が増えれば,「一人当たりの走行距離」は大きくなりますし,「走行距離あたりの死者数」は小さくなります。つまり,そもそもこのグラフで使われている2つの指標は反比例する関係にあるわけです。
では,この記事が当たり前の事象を意味ありげに書いたデタラメなのかというと,決してそういうわけではありません。
次の図は,グラフから数字を抜き出して,横軸に一人当たりの走行距離を,縦軸に走行距離あたりの死者数をとった散布図です。一見して反比例の関係にあることがわかります。

さて,この関係を式で表すと,

のようになります。図の赤い実線は,非線形回帰で上の式のパラメータを推計した曲線です。ここで は死者数を,
は死者数を, は自転車走行距離を,
は自転車走行距離を, は人口を表しています。
は人口を表しています。
さて,この式の両辺に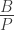 をかけると,
をかけると,
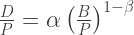
となります。この式の左辺は,人口当たりの自転車事故死者数を表すことになります。
この式をもとに,横軸に「一人当たりの自転車走行距離」を,縦軸に「人口当たりの自転車事故死者数」を取った図を描くと,次の図のようになります。先ほどと同じように,データから上式のパラメータ推計した結果を赤の実線で示していますが,上に凸の曲線になっています。

この図から言えることは,以下の2点です:
- 一人あたり自転車走行距離が長い国ほど,自転車事故で亡くなる人の人口あたりの比率は高い。
- ただしその比率は一人当たり自転車走行距離の増加にともなって逓減(増加率が減少)する。
もうちょっと意訳すると「自転車に乗る人が増えれば増えるほど自転車事故死者は増えるけど,自転車に乗る人が2倍になっても死者は2倍にはならない」という感じでしょうか。







